Method
Click to view full-resolution PDF.
① Necessity of Multi-Verifier Framework
Single verifiers fail to capture the multi-faceted nature of joint audio-video quality and are susceptible to verifier hacking — where the search exploits verifier-specific biases to inflate a single metric, producing outputs with high scores but no genuine improvement in perceptual quality or cross-modal coherence. We experimentally demonstrate that a multi-verifier framework is essential to account for all four key criteria simultaneously: semantic alignment, perceptual quality, audio-video semantic consistency, and precise synchronization.
② Optimal Multi-Verifier Combination
We identify the optimal verifier combination through systematic evaluation. Text-video consistency is prioritized as the primary signal since it most directly influences user satisfaction. We then show that incorporating audio-visual synchronization as a complementary verifier yields the most balanced improvements across all evaluation dimensions — without introducing performance trade-offs between modalities.
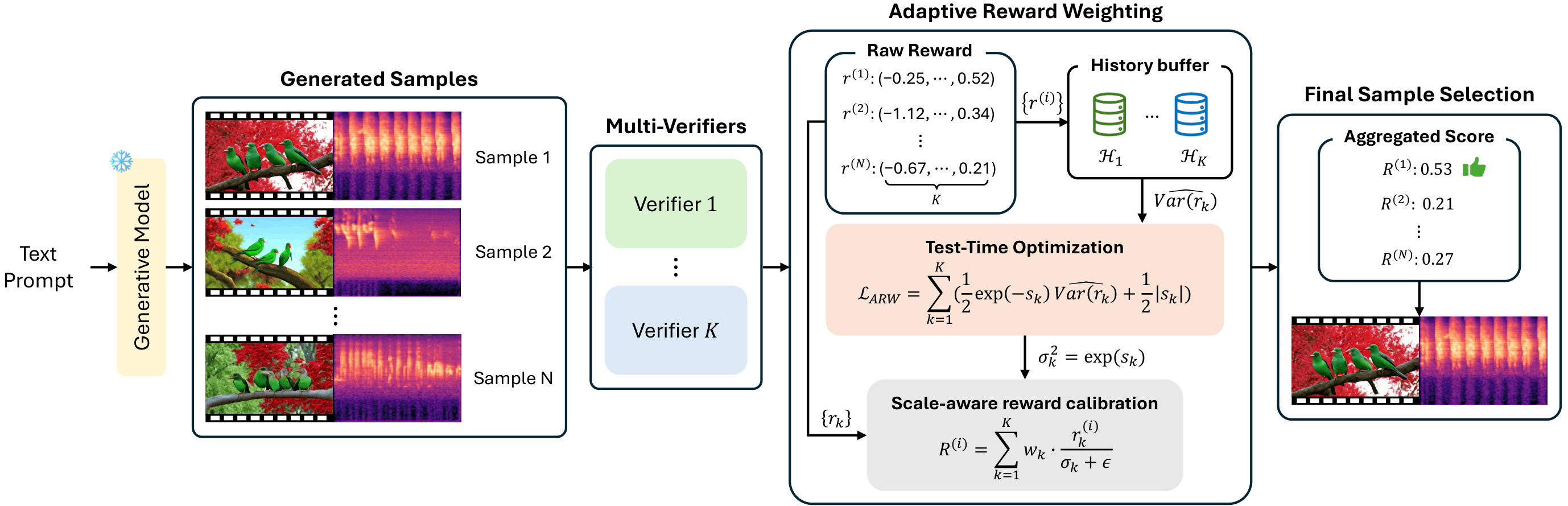
③ Adaptive Reward Weighting (ARW)
To aggregate heterogeneous reward signals with different scales and distributions, we propose ARW — a test-time optimization algorithm that assigns learnable calibration parameters to each reward type. By penalizing high-variance signals, ARW prevents any single reward from dominating the aggregated score, ensuring balanced multi-objective selection without requiring prior knowledge of reward distributions or offline statistics.